What I Learnt about Indexing from MongoDB.Local
A deeper dive into indexing—in MongoDB and beyond!

Published on
Oct 20, 2024
Read time
2 min read
Introduction
For the past two years, I have attended MongoDB.Local in London with my company. A lot of the talks revolve around the slightly different mental model that a NoSQL database like MongoDB uses compared to traditional relational databases like PostgreSQL, especially when it comes to database schema design.
This year, however, I found myself doing a deeper dive on indexing. Though I have been creating indexes for a while now, recently I have been wanting to take a more thoughtful approach to choosing when (and when not) to create an index. Several ideas from the conference talks resonated with me and, in this article, I’ll share some of the key takeaways.
It’s worth noting that most of these principles are applicable to indexing in any database, not just in MongoDB—though there are a few MongoDB-specific tricks that I hope you’ll find useful.
But first, before we dive into more specific details, let’s recap what an index is and why we use them.
Indexing Recap
An index is a data structure that improves the speed of read operations on a database table at the cost of additional writes and storage space. It’s a compromise: used ineffectively, we may end up with rising cloud storage costs or slower write operations; used effectively, we can speed up read operations significantly.
The potential benefits—and costs—grow significantly with the size of the database. Indexes allow us to retrieve a document in O(log n) time complexity, rather than O(n) time complexity, where n is the number of documents in the collection.
If no index is hit for a given query, the database must scan every document in the collection to find the one(s) that match the query—a COLLSCAN. Whereas if an index is hit, the database can use the index, performing an IXSCAN, which is much faster.
Number of items n | COLLSCAN O(n) | IXSCAN O(log n) |
| 1 | 1 | 1.00 |
| 10 | 10 | 4.32 |
| 100 | 100 | 7.64 |
| 1,000 | 1,000 | 10.97 |
| 10,000 | 10,000 | 14.29 |
| 100,000 | 100,000 | 17.61 |
| 1,000,000 | 1,000,000 | 20.93 |
| 10,000,000 | 10,000,000 | 24.25 |
| 100,000,000 | 100,000,000 | 27.58 |
| 1,000,000,000 | 1,000,000,000 | 30.90 |
To me, this is pretty mind-blowing stuff: with a billion documents indexed correctly, we can retrieve a specific document in just 30 operations, rather than a billion operations!
Below is a visual representation of the difference between linear and logarithmic time complexity. I only went up to 50 items, as much more than that makes the logarithmic curve look like a straight line!
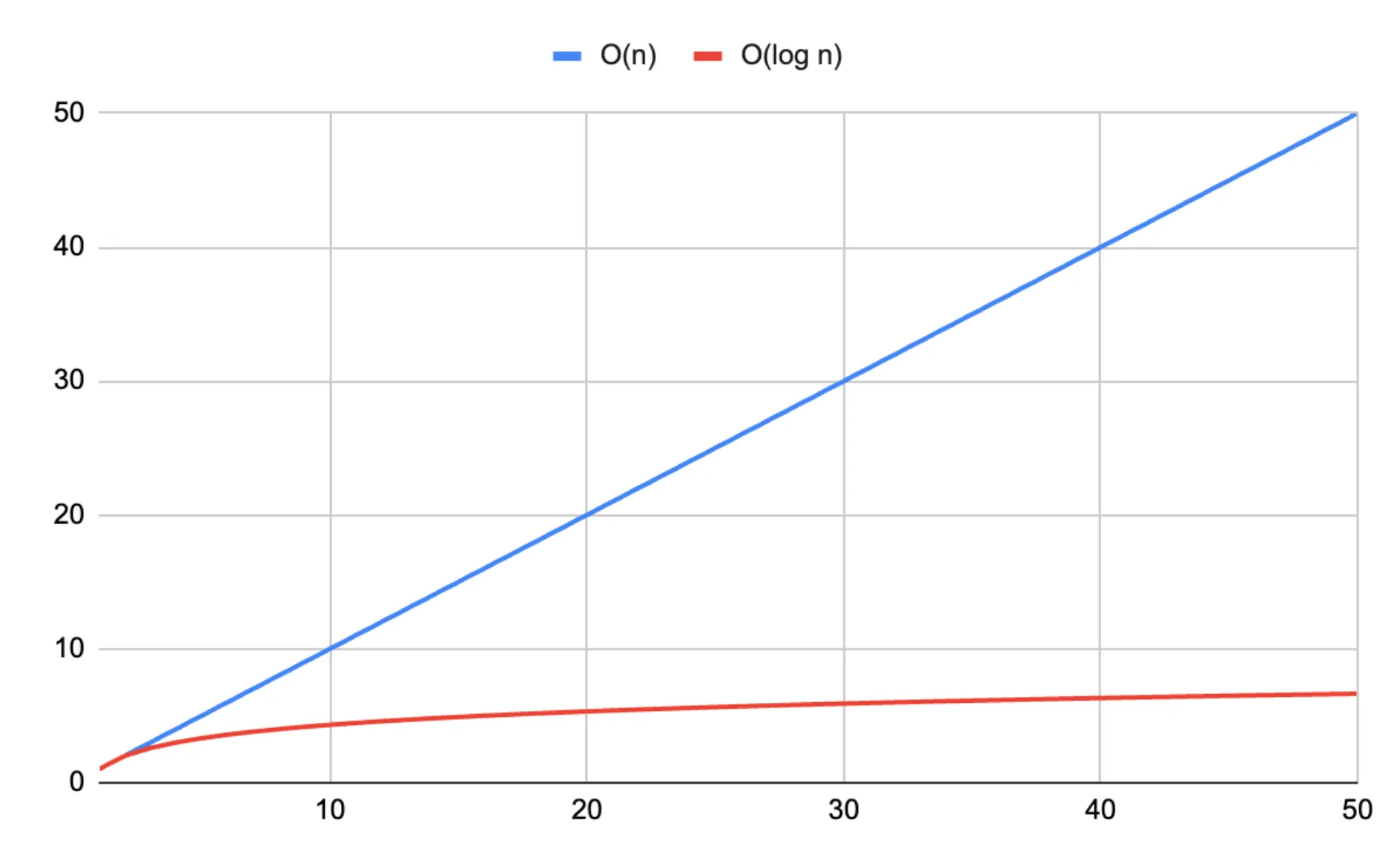
However, the size of the index grows linearly with the size of the database, meaning it has a space complexity of O(n). A collection with a billion documents and a 10 indexes would mean that we have 10 billion index entries to store. Though these entries are smaller than the documents themselves, they can still add up to a significant amount of storage space—potentially terabytes of data, which don’t come cheap in the cloud!
These indexes are stored in a data structure called a B-tree. A B-tree is a self-balancing tree data structure that maintains sorted data. It differs from a binary search tree in that a node can have more than two children.
Below is a visual representation of a B-tree with a maximum depth factor of 2. This is a simplified version of a B-tree, as real-world B-trees have a much higher max depth factor. You can try adding nodes to the tree to see how it self-balances:
Related articles
You might also enjoy...

The State of AI Programming Going into 2026
Have LLMs become a mandatory programming tool?
4 min read
Dec 2025
Focus Doesn’t Scale
How to multitask when you’re wired for deep work
4 min read
Jul 2025
Are We Letting AI Code for Us — and Killing Our Skills?
The trade-off between mastery and speed
3 min read
Jun 2025